
Understanding Weights: Neural Networks vs. Linear Regression
Deon | March 15, 2024, 11:33 a.m.
In the rapidly evolving field of Artificial Intelligence, the concept of weights plays a crucial role in both simple models like linear regression and complex architectures like neural networks. Although weights are fundamental to both approaches, their usage and implications differ significantly. This article explores these differences to help you better understand how these models function and what makes each of them unique.

Linear regression is one of the simplest forms of predictive modeling. It aims to establish a linear relationship between an independent variable (or variables) and a dependent variable. The model can be expressed with the equation in the image above this paragraph. Here, 𝑏₁ represents the weight (or coefficient) for the independent variable 𝑋, 𝑏₀ is the intercept, and ϵ is the error term. The weight 𝑏₁ signifies how much the dependent variable 𝑦 changes for a one-unit change in 𝑋. This weight is constant and does not vary with different values of 𝑋. In a more complex linear regression with multiple independent variables, each variable has its own weight. For instance, if there are two or more independent variables, the equation becomes:

Each independent variable 𝑋₁ , 𝑋₂,...𝑋ₙ, has a corresponding weights 𝑏₁ , 𝑏₂,...𝑏ₙ. These weights are determined during the model training process and remain 𝐟𝐢𝐱𝐞𝐝 once the model is trained. Linear regression weights are straightforward, making the model easy to interpret and understand.
Neural Networks: Flexibility and Adaptability

Neural networks, on the other hand, are inspired by the human brain and consist of multiple layers of interconnected nodes (or neurons). Each connection between nodes has an associated weight and a non-linear activation function; this combination of weights and activation functions is critical in determining the output of the network. Unlike linear regression, neural networks can capture non-linear relationships between inputs and outputs, making them more suitable for use on complex non-linear datasets. In a neural network, the input features are multiplied by their corresponding weights, summed, and passed through an activation function to produce the output. The process can be summarized with the equation: ŷ = 𝜎(𝑤₁𝑋₁ + 𝑤₂𝑋₂ +…+ 𝑤ₙ𝑋ₙ + 𝑏). Where ŷ is the predicted output, 𝜎 is the activation function (e.g., sigmoid, ReLU)., 𝑋ᵢ, are the inputs, 𝑤ᵢ are the weights associated with each input 𝑋ᵢ, and 𝑏 is the bias term. Each input feature has its own weight, and these weights are adjusted during the training process using techniques like backpropagation and gradient descent.
How Weights Are Handle In a Neural Network
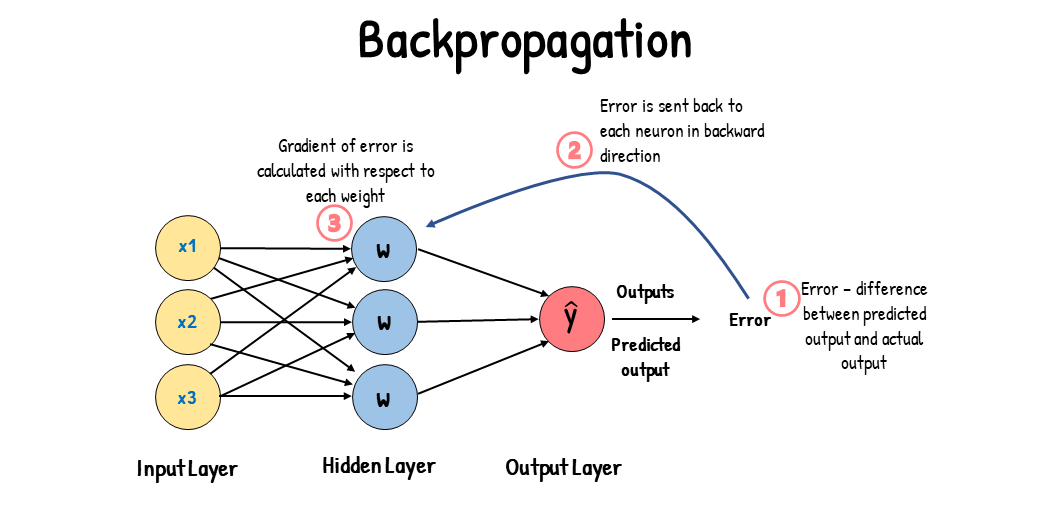
The primary distinction between weights in neural networks and linear regression lies in their adaptability. In neural networks, weights are continuously updated through training iterations to minimize the loss function, enabling the model to learn complex patterns in the data. This is achieved through backpropagation, a process that identifies which neurons contribute to errors and adjusts the weights accordingly. This flexibility makes neural networks suitable for tasks such as image and speech recognition, where capturing intricate relationships is crucial. In contrast, weights in linear regression are determined in a single optimization process to best fit the data, making linear regression effective for simpler, linear relationships.